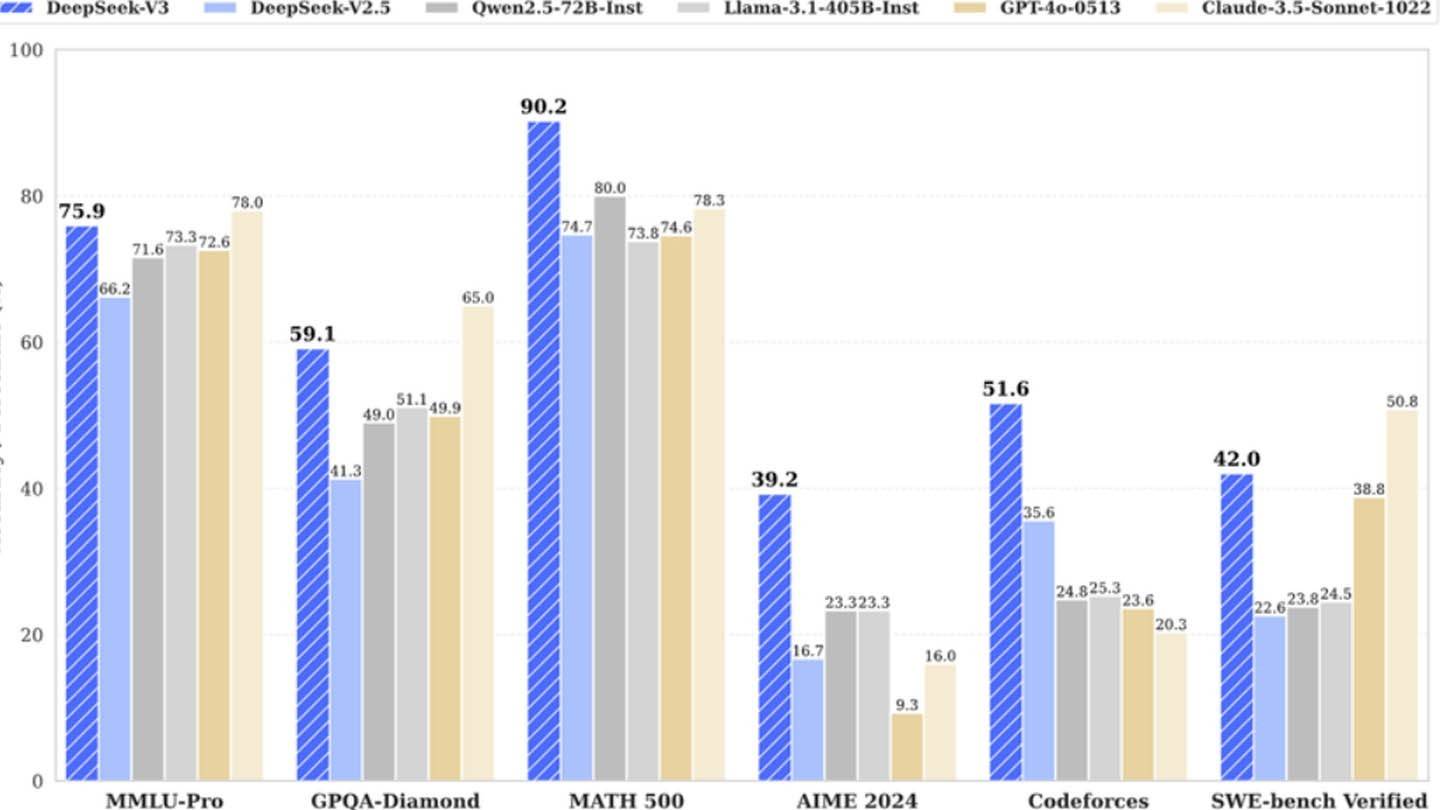
Deepseekの新しいチャットボットには、印象的な紹介があります。中国のスタートアップDeepSeekの製品であるこのAIは、急速に主要な市場プレーヤーになり、Nvidiaの株価の大幅な低下に貢献しています。その成功は、いくつかの革新的な技術を組み込んだユニークなアーキテクチャとトレーニング方法論に由来しています。
マルチトークン予測(MTP):従来の単語ごとの予測とは異なり、MTPは複数の単語を同時に予測し、精度と効率の向上について文セグメントを分析します。
専門家の混合(MOE):このアーキテクチャは、複数のニューラルネットワークを活用して入力データを処理し、AIトレーニングの加速とパフォーマンスを高めます。 Deepseek V3は256のネットワークを利用して、トークンごとに8つをアクティブにします。
マルチヘッド潜在的注意(MLA):このメカニズムは、重要な文要素に焦点を当てています。 MLAは重要な詳細を繰り返し抽出し、重要な情報を見落とすリスクを最小限に抑え、微妙な理解を向上させます。
Deepseekは、2048 GPUのみを使用して、強力なDeepSeek V3モデルに対して600万ドルのトレーニングコストが非常に低いと主張しました。ただし、セミアンアリシスにより、はるかに大きなインフラストラクチャが明らかになりました。約50,000のNVIDIAホッパーGPU(10,000 H800、10,000 H100、および追加のH20を含む)が複数のデータセンターに広がっています。これは、サーバーの総投資額を約16億ドルで、運用費用は9億4,400万ドルと推定されています。
High-Flyer Hedge Fundの子会社であるDeepseekは、データセンターを所有しており、最適化とより高速なイノベーションの実装を完全に制御しています。この自己資金によるアプローチは、柔軟性と意思決定速度を向上させます。さらに、同社はトップの才能を集めており、一部の研究者は主に中国の大学から年間130万ドル以上を稼いでいます。
したがって、600万ドルの数字は、トレーニング前のGPUコストのみを表す重要な控えめな表現であるように見えます。 AI開発への実際の投資は5億ドルを超えています。それにもかかわらず、DeepSeekの合理化された構造により、より大きな官僚的企業と比較して、効率的なイノベーションの実装が可能になります。
Deepseekの成功は、資金提供された独立したAI企業が業界の巨人と競争する可能性を示しています。 「革新的な予算」の請求は間違いなく誇張されていますが、会社の成功は否定できず、実質的な投資、技術的なブレークスルー、非常に熟練したチームに支えられています。競合他社のコストを考慮すると、コントラストは印象的です。 DeepseekのR1モデルの価格は500万ドル、ChatGpt4は1億ドルかかります。明確なコストがあっても、DeepSeekは競合他社よりもかなり安いままです。